Going Nuclear: Modeling Threats to Distributed Systems
It probably won’t come as a shock to you that as I was writing up my last post on IoT and my new Geiger counter I was mentally reviewing all the things that scared the crap out of me had me concerned security-wise. I don’t mean the apocalyptic visions of Fallout, but about the fact that I have a device I don’t necessarily trust sitting on my network constantly feeding data to a remote server without much control by me.
I’m predictable like that.
Upon further review I realized I wanted to write up my thoughts on how I would protect against such an unknown, but really… you just need to stick it on an isolated network. You can’t see me, and I can’t see you. I’ll leave it to the networking wonks to decide what isolated really means in this case.
That of course left me with a very short and very boring post.
It then occurred to me that I’ve never really written in detail about different types of threats or risks or how you model them when developing a system. Of course, I don’t want to write in detail about different types of threats — there’s plenty of content out there already about this sort of thing. What I do want to do though is talk about how you model the risks so you can work through all the potential threats that might exist.
In keeping with the theme (because it’s fun and highly improbable) we’re going to build a fictitious radiation monitoring system just like the uRADMonitor, but we’re going to look at how you would evaluate the risks to such a system and how you might mitigate them.
Disclaimer
I don’t have any affiliation with the uRADMonitor project aside from the fact that I have a device of theirs in my office on my network. I can’t speak to their motivation for building the system and I can’t say what they’ve done to protect their system. This is purely a thought experiment on how I would build and protect a similar system.Additionally, this is not necessarily a model where I’ve listed every possible risk or threat and rigorously verified solutions work. In fact, I’ve left out a number of things to consider.
Remember: it’s just for fun.
Projects are created to solve particular problems (also, sky is blue: report). This monitoring network is no different. We’ll review the problem as we see it, and then we’ll create a design to solve the problem. We’ll then review the design and see what kinds of risks we might find and how we can solve for them as well. We’ll iterate on this a few times and hopefully come up with a secure solution.
Not surprisingly I’ll go off on tangents about things I find interesting and gloss over other things. They may not be pertinent to the discussion at all.
The Problem
Radiation levels affect the health and well being of the population. Sudden significant changes in levels can have dangerous health effects and indicate signs of environmental accidents or geopolitical unrest. An unbiased real time record of radiation levels needs to be created and monitored so appropriate actions can be taken in the event of serious danger.
The Solution
Build and deploy a distributed network of radiation monitoring agents that persist data to a central store so the data can be reviewed by analysts and automatically notify the appropriate people when significant events occur.
If you’ve ever done product design that cryptic answer might be all you need from the product owner. So we need to break that down a bit. We’ve got a whole bunch of agents distributed throughout the world sending data back to a central server. This data should be consumable by analysts (scientists, safety authorities, etc.) either through an API (a program might be analyzing the data), or through a graphical interface (an actual person wanting to review data). These are easy enough to develop — create writable web API’s for the agents, a web portal for the people, and read only web API’s for the programs.
The Risks
I’d say we glossed over the solution a bit, and we did that purposefully because investing a lot of effort into designing a system without understanding the risks is, well, a waste of time. We just need enough to get things moving. We have a good idea of what we want to build for now, so lets try and understand some of the risks. Our initial design looks something like this:
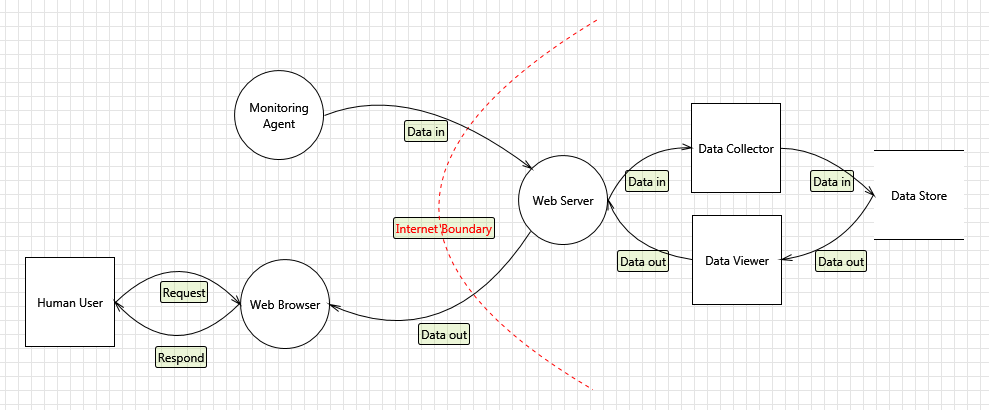
Figure 1: Basic Data Flow Diagram
When we consider the risk of something, we consider the chance that thing might occur. We need to weigh the chance of that thing occurring with the effect it would have on the system. We then compare the cost of the effect with the cost of mitigating the effect and pick whichever one is lower. We generally want the lowest possible level of risk achievable based on the previous formula. In our case it’s actually pretty easy to work out because anything that disrupts the capabilities of the network is considered high risk. Let me see if I can explain why.
The idea of having a distributed network of things connecting back to a central server is not novel. The fairly detailed diagram above could easily be confused with a thousand other diagrams for a thousand other systems doing a thousand different things. There are a lot of commonly considered risks related to this and they can probably be summed up into these properties:
- Server availability – Is the server online and accepting requests whenever an agent wants to check in, or when an analyst wants to review the data?
- Agent availability – Is an agent online, able to measure the things it needs to measure, and have a connection back to the server to check in?
- Data accuracy – Do agents check in data that is measured properly and hasn’t been fiddled with?
This is a pretty broad but reasonable assessment for a number of systems. The risk is that any of these properties answer false because a failure in any one of these properties means the system can’t function as intended. We need to consider what sorts of things can affect these properties.
Here’s the thing: it needs to be available 100% of the time and absolutely accurate. It has the potential to influence the actions of many people regarding things that can kill them. This is one of those things that most security people really only dream about building (we have weird dreams). There can be serious consequences if we fail. Therefore we need to consider even the tiniest chance of something occurring that could affect those three properties and mitigate.
As system designers we need to go nuclear. (yes I know that was a bad pun. I’ll show myself out.)
In our case the system needs to withstand serious catastrophic events simply because it’s intended to monitor serious catastrophic events. If such an event occurs and the system can’t withstand the effects then we’ve failed and the whole point of the project can’t be realized. Conversely, it also needs to withstand all the usual threats that might exist for a run-of-the-mill distributed system.
Normally we would need to do an analysis on the cost of failure so we could get a baseline for how much we should invest, but this is my model and I’m an impossible person. The cost of failure is your life. (muahaha?)
Threats to Server Availability
Interestingly this property is easiest to review, relatively speaking. Our goal is to make sure that everything on the right side of that internet boundary is always available so everything on the left side of the boundary can access it.
 Let’s consider for a moment that we want all the data stored in one single location so we can get a holistic view of the world. Easy enough, right? Just write it all to one database on a server in a datacenter somewhere near the office that has public internet access. We want this server to always be available. That means 100% up-time for a single server. I’ll just go right out and say it: that’s impossible. Consider some of the more mundane things that can cause a server to go offline. We deal with these things every day and because of that there’s always something complaining that it can’t connect.
Let’s consider for a moment that we want all the data stored in one single location so we can get a holistic view of the world. Easy enough, right? Just write it all to one database on a server in a datacenter somewhere near the office that has public internet access. We want this server to always be available. That means 100% up-time for a single server. I’ll just go right out and say it: that’s impossible. Consider some of the more mundane things that can cause a server to go offline. We deal with these things every day and because of that there’s always something complaining that it can’t connect.
- Datacenter network failure
- Server updates requiring a reboot
- Power failure
- Hardware failure
Now, imagine we’ve got thousands of agents checking in every minute. Assuming 5 minutes of downtime for just one of these events and we’re talking 4000-5000 points of data lost. That’s a low assumption though. Hardware failure might mean the server is out of commission for hours or days. And don’t forget: hardware is measured in mean time to failure — odds are pretty good something will fail at some point.
Let’s continue. Consider what happens we start adding more agents. We’re talking global coverage, so a thousand agents probably aren’t going to cut it. We’ll need a few more.
I make no guarantees my math is accurate.
We can take a WAG at the number of agents we’ll need based on a few existing data sets provided by various agencies. The US EPA has their own monitoring network of 130 agents. The US is about 3,805,927 mi² in area. Assuming each monitoring agent is spaced out evenly (they aren’t) we see an average coverage area of 29,276 mi² for each agent. They also check in once every hour. The resolution of the data isn’t great. It’s useless to anyone more than a few miles away from an agent, and nobody would know something serious has happened within enough time to do something about it.
Conversely the USGS NURE program over a period of years measured the radiation levels in great detail by collecting hundreds of thousands of samples across the country, but they were for a single point in time. The resolution is fantastic, but it’s not real-time. We want something in between. Let’s try and get a more concrete number.
According to 2007 census there were 39,044 local governments (lets call them cities for simplicity) in the US. Let’s assume we want 4 agents per city. As of July 1st, 2013 there were 295 cities (again, for simplicity) with a population greater than 100,000 people. Lets also assume we want 10 agents for each one of those larger cities. (Remember, its a WAG)
[(39,044 – 295) x 4] + (295 x 10) = 154,996 + 2950 = 157,946
So that means based on our very rough estimates we need 157,946 agents for just the United States. Each one of those agents would check in every minute, so that means we’re talking 227,442,240 check-ins every single day. Now extrapolate for the rest of the world.
Let’s assume we need 22 times as many agents (world population / US population). That’s 3,474,812 agents, or 5 billion check-ins a day.
This would of course require more analysis. We don’t necessarily want to deploy agents based solely on population density because there would be significant fluctuations in the number of agents per city vs rural areas. The numbers are good enough for our fake model though.
Now, back to our server. We didn’t consider load as a risk, but now we need to, so we add a few more servers. We’ll revisit this in a second. What else might affect the availability of our servers?